DeepSeek技术原理解读及模型安全风险分析
DeepSeek V3 & R1关键技术分析
主要思路:
- 降低训练成本:通过FP8低精度训练、DualPipe双向流水线等
- 降低推理成本:优化MoE负载均衡等
- 优化训练数据:使用 14.8T 高质量、多样化的 token,增加了数学和编程样本的比例,扩大了多语言覆盖范围
- 进一步提升效果:多 Token 预测(MTP)、从 DeepSeek-R1 中蒸馏推理能力等
效果:
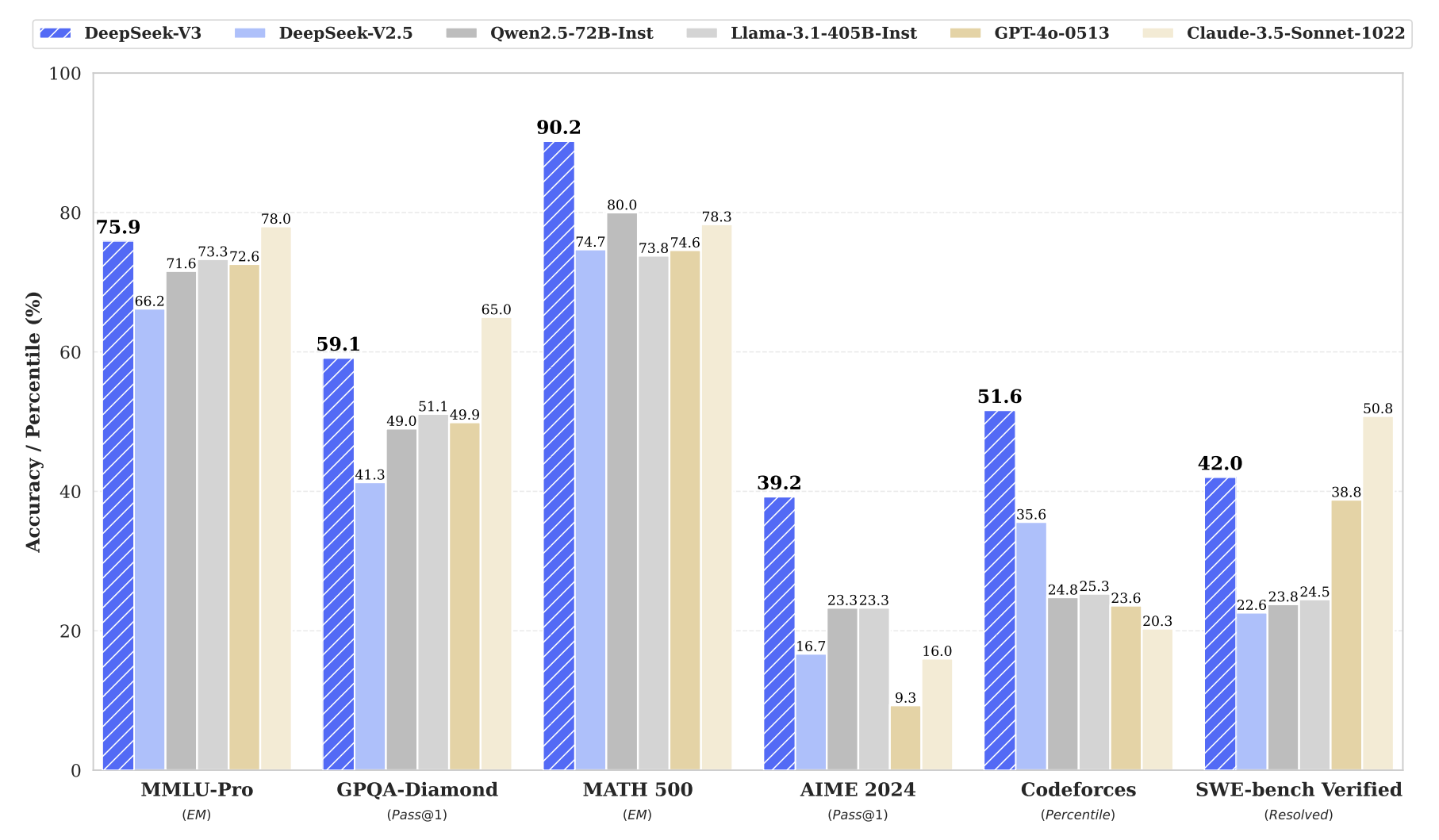
- 在 MMLU、MMLU-Pro、GPQA 等知识性基准测试中,性能与 GPT-4o、Claude-3.5-Sonnet 等领先闭源模型相当。
- 在 代码和数学 基准测试中,取得了最先进的性能,甚至超越了 GPT-4o。
- 在 AlpacaEval 2.0 和 Arena-Hard 的开放式评估中表现出色。
训练成本 :
- 总成本 :278.8 万 H800 GPU 小时,约 557.6 万美元。
- 预训练效率 :每训练 1 万亿个 token 仅需 18 万 H800 GPU 小时,训练过程稳定,无需回滚。
开源情况:
- 技术报告:DeepSeek-V3 Technical Report
- 权重(大小足有671B,FP8精度):deepseek-ai/DeepSeek-V3-Base · Hugging Face
核心:降成本
模型效果好 训练过程快 推理成本低,相比同等性能开源模型训练成本成倍降低

模型结构优化
- MLA技术,降低计算过程中的K, V Cache,降低成本。
- DeepSeek MoE,更多专家模型,总共671B参数,激活37B(相当于小模型的激活量),提高推理效率。
训练优化
- 加入MTP多token预测模块,提高训练效率。
- 二阶段上下文长度扩展 4K->32K,32K->128K。通过在预训练的时候首先去在一个短的上下文上去训练一个基础的一个模型,再经过微调去扩展到一个比较长的一个上下文,减少训练时间。
- 自研大模型训练加速框架HAI-LLM,融合多项性能优化工程技巧,在超大规模训练任务中首次使用FP8混合精度提升训练效率
通信优化
- DualPipe算法减少bubble
- ALL2ALL通信和计算掩盖
内存优化
- 重采样RMSNorm和MLA上采样,以算换存
- 将EMA权重存储在CPU内存,异步更新
架构创新
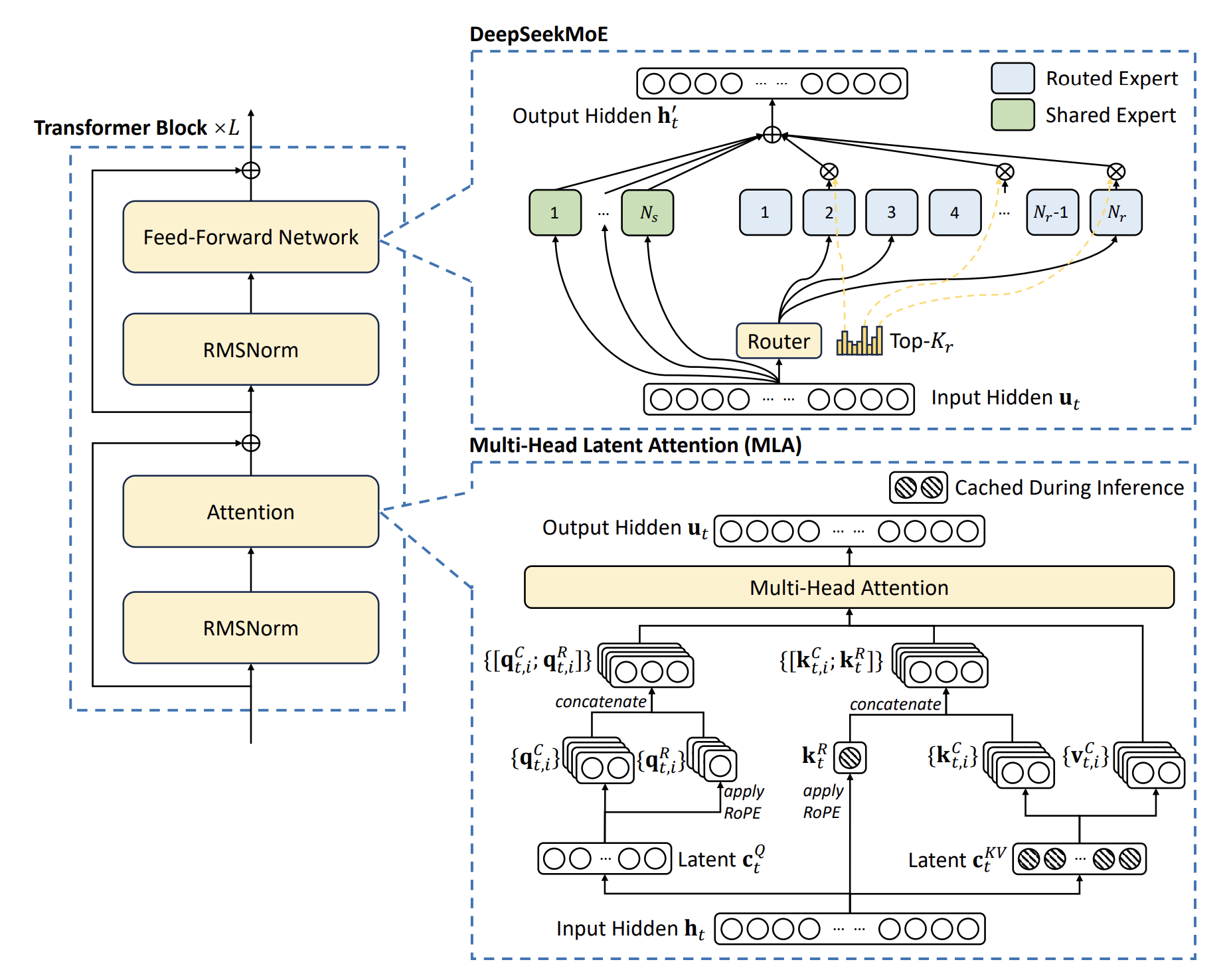
DeepSeek在模型主框架上与主流LLM模型并无差异,主要创新点集中在Transformer块。差异点在于:
- 提出MLA结构,改进Attention计算方式,缩小KV Cache缓存,提高推理速度。
- 提出DeepSeek MoE架构,激活部分参数,降低推理成本,提高推理速度。
Multi-Head Latent Attention
MLA技术:MLA继承自DeepSeek V2的MLA架构,通过将多头注意力的Key和Value映射到低维共享潜在向量空间,实现动态压缩KV缓存,替代传统的逐头存储方式,且并不会导致明显的性能下降。
原始Attention的缺点:
- 每次计算Attention时都需要重新计算键值对,导致大量重复计算。
- 显著增加计算开销,降低推理效率。
使用KV Cache的原因:
- KV Cache用于存储计算Attention时的键值对,避免重复计算。
- 支持高效的自回归生成,提升推理性能。
减少KV Cache的目的:
- 在更少的设备上处理更长的上下文。
- 提升推理速度和吞吐量,降低推理成本。
KV Cache的挑战:
- KV Cache随输入长度动态增长,可能超出单卡或多卡显存限制。
- 跨设备通信带宽较低,影响性能,因此需尽量减少跨设备部署。

为什么降低KV Cache的大小如此重要?
众所周知,一般情况下LLM的推理都是在GPU上进行,单张GPU的显存是有限的,一部分我们要用来存放模型的参数和前向计算的激活值,这部分依赖于模型的体量,选定模型后它就是个常数;另外一部分我们要用来存放模型的KV Cache,这部分不仅依赖于模型的体量,还依赖于模型的输入长度,也就是在推理过程中是动态增长的,当Context长度足够长时,它的大小就会占主导地位,可能超出一张卡甚至一台机(8张卡)的总显存量。
在GPU上部署模型的原则是:能一张卡部署的,就不要跨多张卡;能一台机部署的,就不要跨多台机。这是因为“卡内通信带宽 > 卡间通信带宽 > 机间通信带宽”,由于“木桶效应”,模型部署时跨的设备越多,受设备间通信带宽的的“拖累”就越大,事实上即便是单卡H100内SRAM与HBM的带宽已经达到了3TB/s,但对于Short Context来说这个速度依然还是推理的瓶颈,更不用说更慢的卡间、机间通信了。
所以,减少KV Cache的目的就是要实现在更少的设备上推理更长的Context,或者在相同的Context长度下让推理的batch size更大,从而实现更快的推理速度或者更大的吞吐总量。当然,最终目的都是为了实现更低的推理成本。
MLA架构中KV共享同一个存储张量,且引入低秩投影,有效减少KV Cache(下图中仅阴影部分需要存储)。用计算换存储,引入额外的计算量,但相比存储消耗,收益更大。

MLA架构:1)分别对Query、Key-Value pair进行低秩压缩;2)使用RoPE获得位置信息;3)使用MHA计算得到输出。
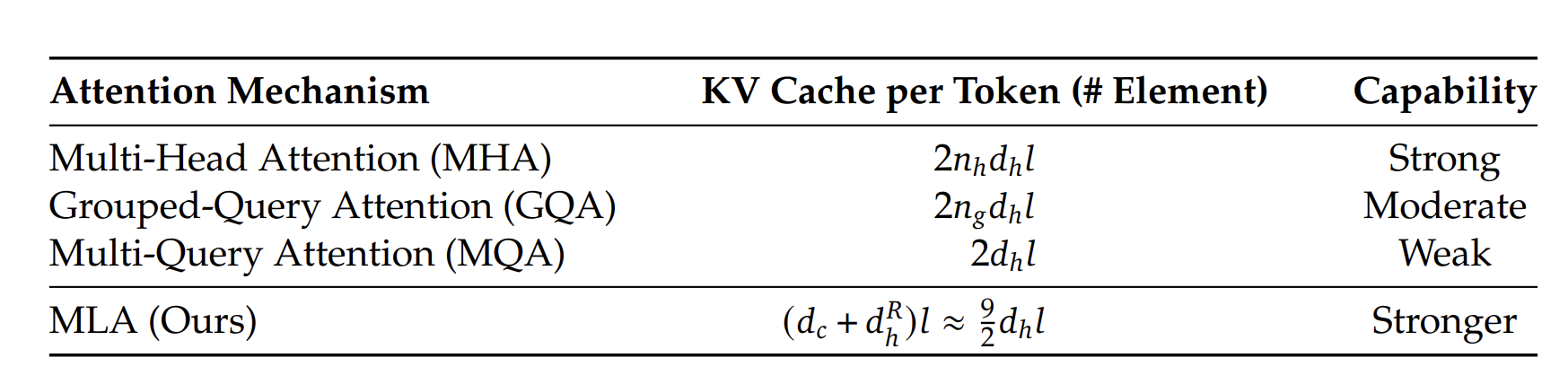
对DeepSeekv3而言,\(n_h=128\),MLA可以将KV Cache降低为 \(\frac{\frac{9}{2}}{2n_h}=1.7\%\)
DeepSeek MoE
DeepSeek MoE技术:DeepseekMoE通过精细分割专家、引入共享专家和优化路由选择,解决了传统MoE中专家知识重叠和负载不均衡的问题。具体包括:将专家细分为更多小专家以增强知识分解能力,隔离共享专家以捕获通用知识,并通过专家级和设备级平衡损失优化路由选择,避免路由崩溃和计算瓶颈,从而提升模型在处理复杂任务时的效率和准确性。
- Dense模型:对所有输入使用全部参数进行计算,计算成本高但实现简单。
- MoE模型:通过路由机制动态激活部分专家网络的参数进行计算,降低了计算成本,同时支持扩展模型规模以提升性能。

精细分割专家:
- 增强知识分解能力:细分为多个小专家,使每个专家专注于更细粒度的任务,提升专家专业化水平。
- 提高组合灵活性:激活专家组合的灵活性显著增强,可动态选择更合适的专家组合,提升任务处理能力。
引入共享专家:
- 学习通用知识:共享专家专门用于学习通用知识,避免其他路由专家重复学习通用知识,减少参数冗余。
- 提升参数效率:通过隔离共享专家,路由专家可以更专注于学习独特知识,提高模型参数利用效率。
优化路由选择:
- 避免路由崩溃:确保每个专家都能获得足够的训练机会,避免模型总是选择少数专家而忽略其他专家。
- 缓解计算瓶颈:确保不同设备上的专家负载均衡,避免计算资源浪费和瓶颈问题,提高分布式计算的效率。
训练方法创新
Multi-Token Prediction
DeepSeek MTP技术:大语言模型传统上采用单个token预测训练方式,即每次只预测下一个token。 DeepSeek V3基于META提出的多token预测方法,进行了改进,采用链式结构而非并行结构,同时保持完整的因果链。这种改进既保留了多token预测的优势,又通过维持因果关系来提升预测质量。不仅提升了模型性能,还改善了模型的泛化能力。
传统大模型采用自回归方式逐token预测:
- 训练效率低:每次在生成一个token的时候,都要频繁跟访存交互,加载KV-Cache,再通过多层网络做完整的前向计算。对于这样的访存密集型的任务,通常会因为访存效率形成训练或推理的瓶颈。
- 长文本建模能力弱:一次只学习单个token,上下文依赖弱,容易陷入局部最优解。

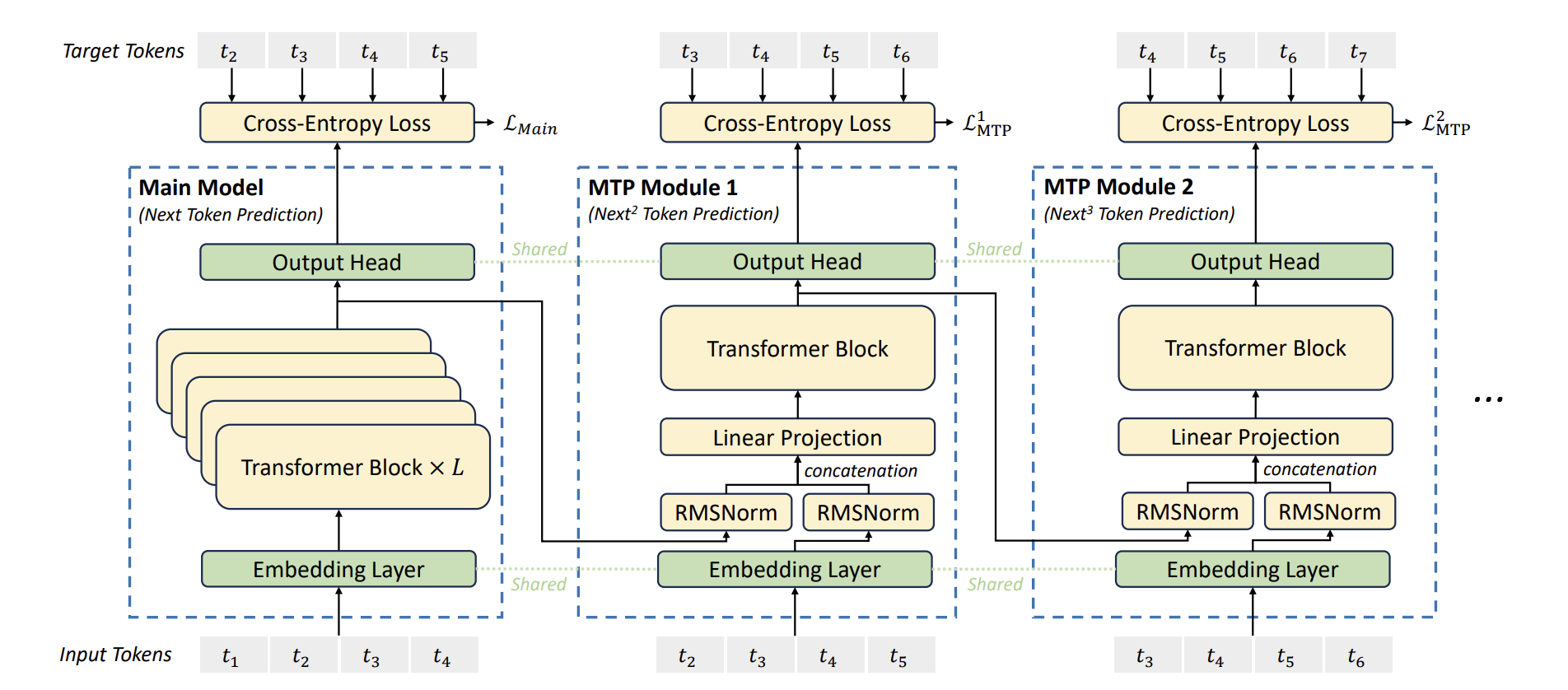
DeepSeek V3 MTP:
- 主网络结构中接入2个预测头,针对输入token \(t_i\)分别预估后续的\(t_{i+1}\), \(t_{i+2}\)
- 预测头之间是串行架构,预测第 \(i+2\) 个token时,会把第 \(i+1\) 个token也作为输入,保证完整的序列推理链实现串行预测
- 一次预测多个token,有效提升训练性能,次token的接受率稳定在85%+,训练时推理速度提升1.8倍
- 共享Embedding层和输出头减少内存开销
- MTP能够增强有监督训练信号,帮助模型预先规划对于token的组织和表达,提高泛化能力
DualPipe and Computation-Communication Overlap

当前问题
当模型规模特别大时,通常需要将其拆分为多个子模块,并分配到多个计算设备上进行并行计算。在此过程中,设备之间需要进行数据通信。当一个设备完成其计算任务后,必须将结果传输给下一个设备,以便后续计算任务能够继续执行。然而,这种数据通信过程会导致部分设备处于空闲状态,从而造成计算资源的浪费。
DeepSeek解决方案
- 更细分工:DualPipe把每个GPU的任务分得更细,比如让一个GPU同时负责模型的开头和结尾部分。这样,GPU之间可以同时干活,不用总是等着别人。
- 双向流水线:普通的流水线是单向的,比如数据从GPU 1传到GPU 2,再传到GPU 3。DualPipe让数据从两头同时传,比如GPU 1和GPU 8同时开始干活,这样中间的GPU也能更忙起来,减少了等待时间。
- 优化通信:DualPipe还改进了GPU之间的通信方式,让数据传输更快,减少了通信占用的时间。
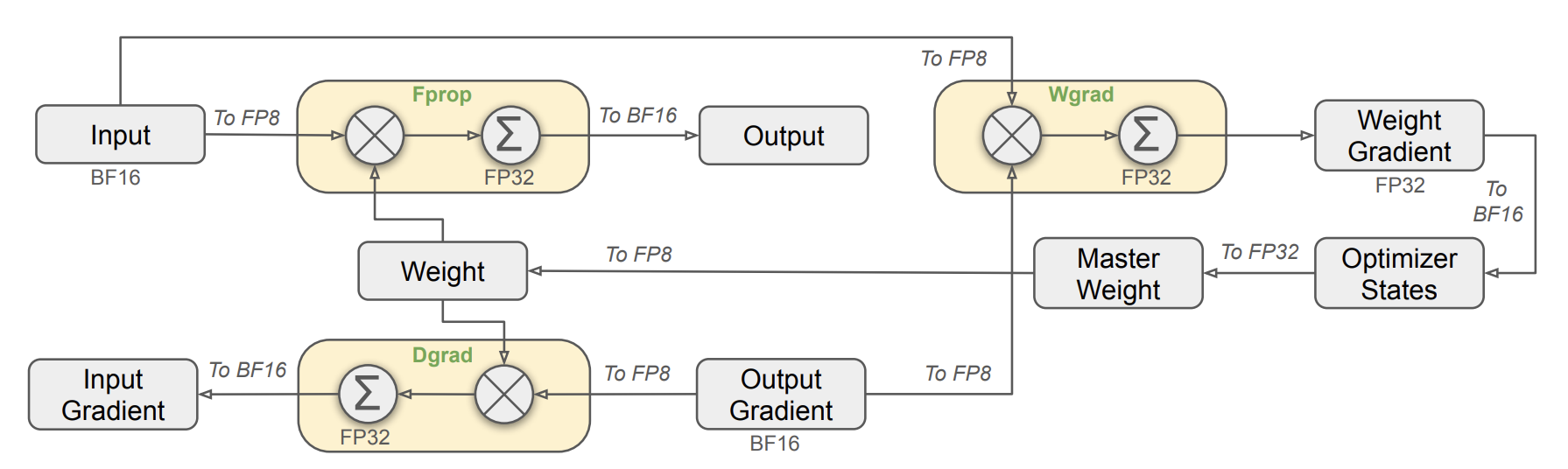
FP8混合精度训练
| 格式 | 位数 | 精度 | 动态范围 | 计算速度 | 内存占用 | 适用场景 |
|---|---|---|---|---|---|---|
| FP32 | 32 位 | 高精度 | 非常大 | 慢 | 大 | 传统高精度计算 (如科学计算) |
| BF16 | 16 位 | 中等精度 | 较大 | 较快 | 中等 | 深度学习训练 (兼顾精度和效率) |
| FP8 | 8 位 | 低精度 | 较小 | 非常快 | 小 | 低精度训练 (追求极致效率) |
当前问题
训练大模型太贵了!FP8低精度训练可以大幅减少计算和内存开销,但直接使用 FP8 会导致数值不稳定,模型训练可能失败。因此,需要找到一种方法,既能享受 FP8 的高效,又能避免它的缺点。
DeepSeek解决方案
- 精度解耦:把模型的不同部分分开处理,对不敏感的部分用 FP8,对敏感的部分保持高精度(如 BF16 或 FP32)。
- 自动缩放:动态调整数据的缩放比例,确保数值在 FP8 的范围内,避免溢出或精度丢失。
- 细粒度量化:对数据进行分组缩放,比如每 128 个通道一组,既保证精度又提高效率。
- 递增累加精度:在计算过程中,先用 FP8 快速计算,隔一段时间再用高精度(FP32)累加结果,减少误差积累。
DeepSeek R1训练过程
DeepSeek-R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能。 DeepSeek-R1以 DeepSeek-V3-Base(671B) 为基础模型,使用GRPO算法作为RL框架来提升Reasoning性能。开源发布了6个基于DeepSeek-R1蒸馏的更小稠密模型( Qwen/Llama 1.5B, 7B, 8B, 14B, 32B, 70 )

DeepSeek V3, R1和R1-Zero区别:
- R1-Zero 基于 DeepSeek-V3-Base,通过 RL (强化学习) 训练,无 STF (监督微调),具备AI自我进化范式。
- R1 则基于 R1-Zero,增加STF(监督微调),先利用少量人工标注的高质量数据进行冷启动微调,再进行 RL。
关键技术点:
- DeepSeek-R1-Zero直接基于V3 Base做RL,不依赖SFT初始化,模型依然能自己学习到推理能力。
- 奖励模型是基于规则的,Accuracy rewards(答案的正确性)和Format rewards(强制思考过程在
<think></think>之间) - 提出了一种提高模型推理能力的训练流程,可生成高质量推理数据。
DeepSeek R1-Zero
DeepSeek R1-Zero 训练核心思路:1. 不做监督微调 2. 强化学习中放弃过程性奖励,直接根据最终结果及输出格式作为奖励函数
flowchart LR
A["DeepSeek-V3-Base"] --> B["强化学习(GRPO)
规则奖励函数"]
B --> C["DeepSeek-R1-Zero"]
- 正确性奖励:评估response是否正确(数学,代码,逻辑)
比如带有确定结果的数学问题,模型需要提供指定格式的最终答案,来增强基于规格的判别正确性。比如对于leedcode问题,针对预设的测试用例可以通过编译器生成反馈信号。 - 格式奖励:评估输出格式是否符合要求
另外还采用了基于格式的奖励,强制模型将思考过程放在<think> </think>标签之间。
训练模板:推理过程和答案包裹在标签里面的形式 <think> reasoning process here </think><answer> answer here </answer>

随着RL的训练进行,模型的输出逐渐变长,逐渐学习推理能力 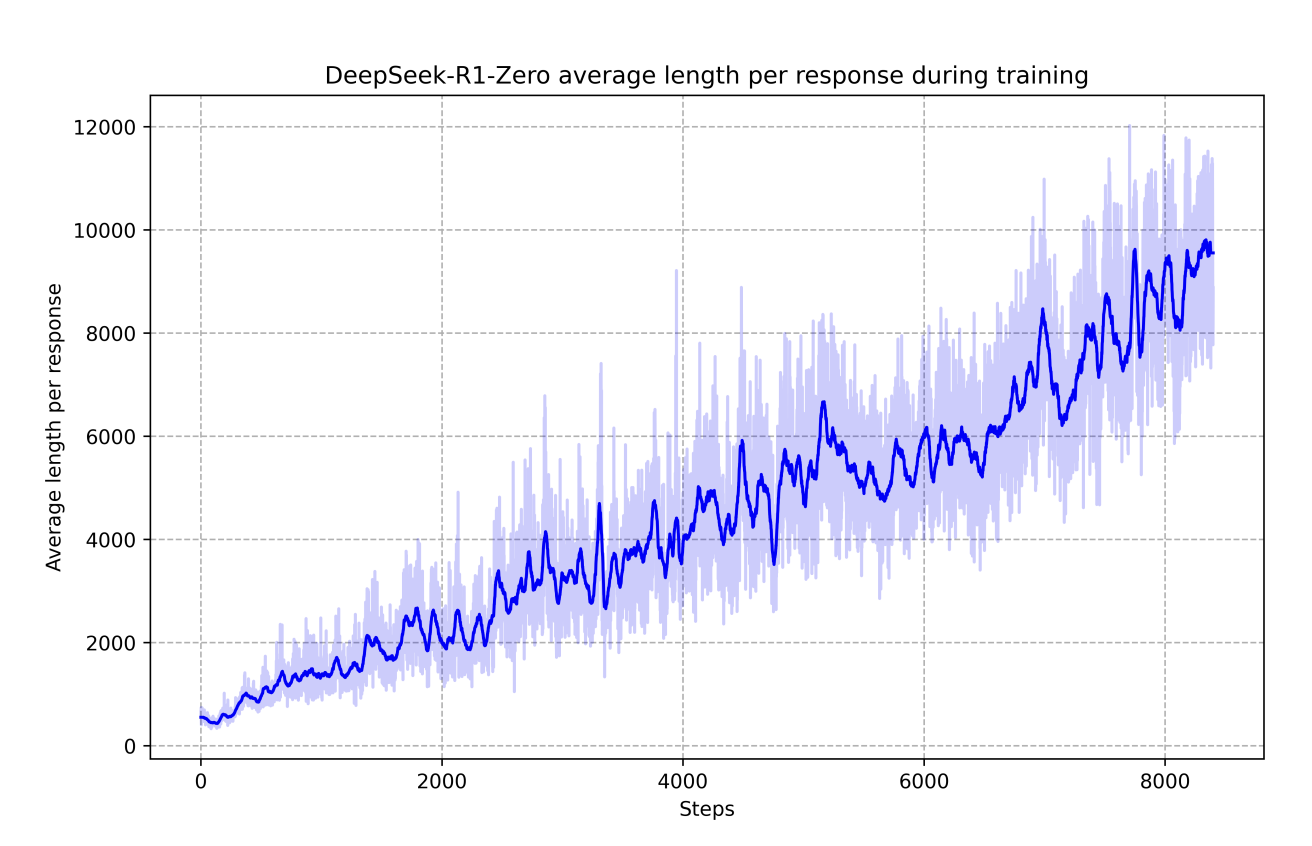
最终结果:推理能力提升,但回答格式混乱、语言混杂
DeepSeek R1
DeepSeek R1训练核心思路:1. 通过SFT+RL等训练方式获得可用模型构造高质量数据集 2. 利用高质量数据集遵照V3训练pipeline对V3 base模型做SFT和RL训练,得到R1模型。
DeepSeek-R1训练过程分为两阶段四个步骤,目标:
- 通过少量高质量数据作为冷启动,提升推理能力和加速收敛
- 训练一个用户友好的模型,使其产生清晰连贯的思维链CoT,还能表现出强大的通用能力
第一阶段:训练出一个可用模型生成高质量数据集
冷启动SFT(约几千条)
数据集:
- Few-shot:带有long cot的例子作为few shot,引导模型生成回答。(V3-Base)
- Zero-shot:直接在prompt中要求模型输出带有思维链的回答。(V3-Base)
- 部分DeepSeek-R1-Zero输出
- 人工做后处理完善结果
数据格式:
- <问题,思考过程,回答>
微调:以DeepSeek-V3-Base为基础模型微调
目的:训练一个指令性遵从较好的模型。
模型:DeepSeek-R1-SFT-1
强化学习
数据集(同R1-Zero):
- Math, Code,逻辑推理等…
数据格式:
- <问题,回答>
数据集数量未知
基于GRPO算法的RL训练:
- 训练奖励函数同R1-Zero一致
提高模型在具有明确解决方案的问题中的推理能力。
目的:学习推理能力,训练具有一定推理能力的模型,用于自动化大规模生成最终训练的数据集。
模型:DeepSeek-R1-RL-1
第二阶段:使用第一阶段高质量数据+常规RL训练,得到R1模型
拒绝采样+SFT
收集SFT数据:只包含问题,不包含答案。
推理数据:基于前一阶段 DeepSeek-R1-RL-1 执行拒绝采样生成推理轨迹。每个提示采样多个响应,并保留正确的响应,共收集600K训练样本
非推理数据:复用 DeepSeek-V3 的 SFT 数据集的一部分,共收集200K。
在 DeepSeek-V3 base 模型上用800K样本做 2epoch SFT 训练。
目的:这个阶段的模型主要是解决 R1-Zero 存在的可读性差和语言混乱的问题。
模型:DeepSeek-R1-SFT-2
全场景强化学习
目的:这个阶段的RL训练主要是提高模型推理能力。以及进一步对齐人类偏好,提高模型的有用性和无害性。训练过程同V3一致。
模型:DeepSeek-R1
Simple test-time scaling: 1000条SFT数据微调实现O1-like推理
核心概念:
Test-time Scaling是一种在模型推理阶段利用额外计算资源提升性能的技术,其核心思想是通过引入更多计算或复杂策略,使模型在生成答案时进行更深入的思考或多次验证,从而提高输出的准确性和可靠性。
核心贡献:
- 提出了一种非常简单的Test-time Scaling方式, Budget Forcing
- 强制结束:若超过最大token数量,强制结束思考过程,并输出答案。
- 延长思考:若提前结束思考,则添加
Wait token来鼓励模型进行更多的探索。
- 构建高质量小规模数据集微调模型,验证方法有效性。
启发:
- 大部分模型都有更强的推理潜力,需要被激活
- 训练数据质量比数量更重要
总结
- 高质量数据对提升模型推理能力至关重要。通过蒸馏大模型数据构建高质量数据集,是提升小模型性能的最有效方法之一。
- 当前LLM普遍具备更强的潜在推理能力,可通过Test time Scaling技术激发。
- 模型内生安全能力的提升可能仍需依赖SFT,因为RL仅在具有明确结果和规则的数据集上表现出良好的推理能力,而内生安全对逻辑性的要求可能相对较低。
- 数学、代码等数据,具有高度结构化和明确的逻辑规则,结果通常是确定性的,可以通过形式化方法进行验证。
- 内容安全数据,通常是开放域的、非结构化的(如文本、图像、语音)。涉及主观判断(例如,什么是“有害内容”可能因文化、语境而异)。
- 模型能力越强可能越容易遭受攻击,如海绵样本、越狱等。攻击者还可能通过控制思维过程来操纵模型输出。
R1模型安全风险分析
模型安全(后门)
模型安全可使用业界SOTA的LLM模型后门检测工具 BAIT(发表于S&P 2025)进行测试,使用DeepSeek-R1生成的推理数据训练出的系列模型暂未发现植入的模型后门。
生成内容安全(越狱、隐私)
思维链/Chain-of Thought (CoT)
R1的慢推理其实是思维链发展来的,目前LLM普遍可以生成思维链,但不会主动触发。需要提示词触发模型生成思维链,思维链内容作为有效信息引导模型给出正确回答。 
- CoT的应用(zero-shot or few shot):提升模型在特定问题上回答的准确性、规范性,数据生成等;突破模型安全边界,利用模板、违规问答等方式诱导模型输出有害内容。
- CoT的不足:1)用户需要根据问题去设计prompt以引导大模型进行reasoning;2)reasoning过程严重依赖于输入的prompt的优劣。
DeepSeek-R1的“慢思考”、Reasoning可以有效提升内生安全防护,但开辟了另外的攻击面
慢思考有效提升内生安全防护
DeepSeek-R1在思维链中可主动意识到要保护隐私数据,通过慢思考提醒自己,答案中涉及的隐私信息必须是随机生成、虚构、测试数据
- 能意识到和敏感信息相关的数据应当是“虚构的”“测试数据”
- 针对用户对敏感信息的询问,能意识到要“随机生成”答案
- 甚至可能意识到“用户正在测试我是否存在漏洞”

DeepSeek-R1在reasoning过程中对用户的合理需求以及非法需求分别进行了分析,并得出结论:要在安慰用户的同时不提供非法信息

对比DeepSeek-V3被越狱成功输出真实的激活码


但是慢思考不能完全避免有害回答,可能出现在思维链中明确意识到要避免有害回答,但答案中依然出现有害回答。
根本原因:Faithfulness(幻觉的一种)不足,即没有完全依据思维链生成回答。
结论:慢思考有助于避免有害回答,但不完全可靠,风控依然是必要的。
慢思考开辟了另外的攻击面
DeepSeek-R1在思维链用了<think><answer>等标签,存在标签伪造风险,可植入思考过程、历史答案


需要警惕提示词中标签的来源,避免思维链伪造,有更多潜在的不安全标签,引入的风险待探索。
应用安全(智能体劫持、海绵样本)
同时暴露思维链让对抗变更容易,暴露思维链 = 暴露大模型的思考思路 -> 让对抗(越狱、劫持)更有的放矢。根本原因是反馈信息从“劫持成功与否”这个二元的反馈变成了整个推理过程,具备了更多信息。
例如在Tree of Attacks: Jailbreaking Black-Box LLMs Automatically 中就介绍了TAP: 一种迭代式越狱话术优化方法。同时在Cisco测试报告(Evaluating Security Risk in DeepSeek and Other Frontier Reasoning Models)中表示基于R1反馈信息优化越狱话术,可实现100%攻击成功率。

此外,DeepSeek在RL训练中放任思维链变长,更容易触发海绵样本:
- 方式1:“写出尽可能多的xxx”
- 方式2:稍微有点复杂的数学问题
- 方式3:解释一个矛盾的命题

大模型易被上文distract,不相干的reasoning内容反倒会削弱模型能力;reasoning过程易陷入死循环、发散时较难停止,因此更容易遭受海绵攻击。