CVE-2022-3901:利用DirtyCred进行容器逃逸
CVE-2022-3910是一个io_uring上的UAF,可以通过DirtyCred很方便的提权,但我们需要覆盖/proc/sys/kernel/modprobe来尝试容器逃逸。
文中代码片段来自Linux kernel v6.0-rc5
io_uring相关组件介绍
io_uring 子系统由Jens Axboe创建,用于提高 I/O 操作(文件读/写、socket发送/接收)的性能。一般来说此类需要与内核交互的 I/O 操作会使用系统调用 (syscall) ,但因为需要在用户态和内核态之间进行上下文切换,会产生大量开销,可能会对执行大量此类 I/O 操作的程序(例如 Web 服务器)产生很大的性能损失。目前计划将其集成到 NGINX Unit 中。io_uring 由内核子系统(主要位于fs/io_uring.c)和用户态库(liburing)组成。
io_uring 不会对每个请求使用系统调用,而是通过提交队列 (SQ) 和完成队列 (CQ)两个环形缓冲区实现用户和内核态之间的通信。用户态程序将 I/O 请求放在 SQ 上,内核将它们拿出来并处理,完成的请求放在 CQ 上,同时允许用户态程序查看处理的结果。
SQ和CQ操作是异步的:向SQ添加请求永远不会阻塞,除非队列已满。
io_uring 可以配置为轮询SQ 是否有新请求,或者使用系统调用io_uring_enter来通知内核存在新请求。然后内核可以在当前线程中处理该请求,或者将其委托给其他内核工作线程。
Jens Axboe 的幻灯片中介绍了漏洞相关的两个重要组件。
Fixed files
Fixed files, or direct descriptors, 可以被看作 io_uring 特定的文件描述符.io_uring 会维护所有已注册文件的引用来减少操作文件描述符导致的额外开销,只有当fixed files未注册或 io_uring 实例被关闭之后才会释放此引用。
Ring messages
io_uring 支持环之间的消息传递io_uring_prep_msg_ring()。根据文档所述,此操作会在目标环中创建一个 CQE,并将其res和user_data设置为用户指定的值。
如此处所述,此功能可用于唤醒在环上等待的休眠任务,或者只是传递任意信息。
CVE-2022-3910
CVE-2022-3910 是因为io_msg_ring()函数不正确的更新引用计数。源文件在这里,相关代码片段如下所示:
1 | |
通过patch中找可以了解详细的问题原因。
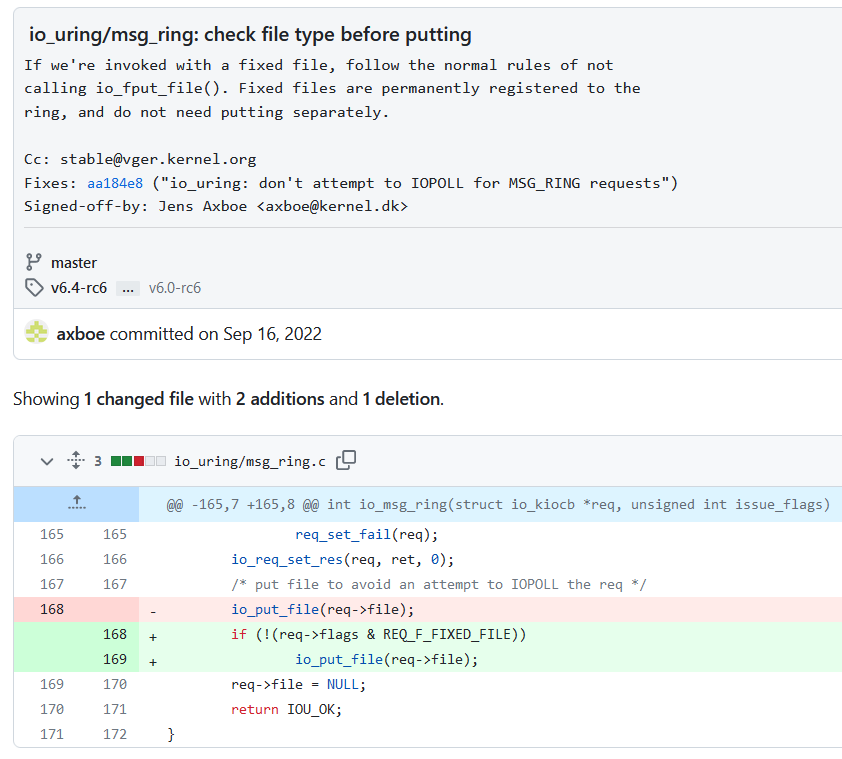
通常io_uring 的消息传递功能需要与另一个 io_uring 实例对应的文件描述符。如果我们传入其他引用,就只会调用io_put_file()并返回错误。
如果我们传入一个Fixed files,io_put_file()仍然会被调用,导致引用数-1,但实际上我们没有获取对该文件的额外引用。
漏洞影响
io_put_file()是fput()的wrapper。在这里可以看到源码,主要代码如下:
1 | |
所以我们只需要重复触发漏洞直到引用计数降至0就可以释放对应的file结构体,同时io_uring会继续保留对其的引用,从而达成一个经典的UAF。
poc如下:
1 | |
正常的利用方式可以通过跨缓存堆喷覆盖sk_buff的析构函数(不是sk_buff->data,因为它的最小分配太大了)以获得执行控制,exp如下: CVE-2022-3910.rar
DirtyCred
在我之前的一篇文章DirtyCred与CVE-2021-4154漏洞分析中详细介绍了DirtyCred的原理和利用方式,其主要核心思想就是Attacking Open File Credentials.
面临的困难
一般来说,DirtyCred的利用方式是通过打开/etc/passwd来添加具有 root 权限的新用户,但我们这里准备尝试利用/sbin/modprobe。
当我们尝试执行具有未知魔数(magic header)的文件时,内核将以root 权限从 root 命名空间调用全局内核变量modprobe_path指向的二进制文件(默认为/sbin/modprobe)。
所以我们只需要把/sbin/modprobe用以下 shell 脚本覆盖:
1 | |
当我们尝试执行具有无效魔数头的文件时,内核就会执行上述脚本,创建/bin/sh 来获取root shell。
但实际上这种利用方式在容器化的环境中无效,因为在容器的命名空间中无法直接访问/sbin/modprobe,modprobe_path会被定位到/proc/sys/kernel/modprobe。
/proc文件系统
根据官网文档的定义,/proc作为一个伪文件系统,负责充当内核中内部数据结构的接口,可用于获取有关系统的信息并在运行时更改某些内核参数(sysctl)。其中/proc/sys子目录允许我们通过写文件的方式一样修改各种内核参数的值。例如/proc/sys/kernel/modprobe会直接指向内核全局变量modprobe_path,修改该“文件”将对应地更改modprobe_path的值。
当然,如果我们不是 root,我们就没办法向/proc/sys/* 中写入任何内容。但这并不是一个大问题,我们可以利用传统的DirtyCred去写入/etc/passwd来实现本地权限提升。
需要注意的是这些对文件的操作需要特定的处理函数,其中/proc/sys/*与file结构体相关联的f_op会被设置为proc_sys_file_operations。但是inode加锁依赖于假设ext4_buffered_write_iter()可以成功写入目标文件,而对/proc/sys/*文件执行会导致未定义行为,返回错误代码。
而为了成功利用DirtyCred,我们必须在调用写入处理程序之前替换file结构体,这意味着有如下竞争窗口:
1 | |
可以看出来窗口很小,我们需要想办法扩大窗口。
A new target: aio_write()
内核 AIO 子系统(与 POSIX AIO 不同)是一个有点过时的异步 I/O 接口,有点像 io_uring 的前身。我们可以尝试利用其中的aio_write()函数,如果我们通过内核 AIO 接口请求写入系统调用,该函数就会被调用:
1 | |
aio_setup_rw()会使用copy_from_user()从用户态复制iovec,同时它位于我们的竞争窗口内(在权限检查之后,但在写入程序处理完成之前)。因此,如果我们有权访问userfaultfd或FUSE,我们就可以稳定的利用这个竞争窗口,从而允许我们将写入操作重定向到/proc/sys/kernel/modprobe.
但是一般来说,不太会有人在容器内启用 FUSE 或为 userfaultfd 打开内核页错误处理。所以看上去利用上述技术所需的条件过于严格,无法在一般的现实世界利用场景中发挥作用。
注意:从技术角度来说,即使 userfaultfd 内核页错误处理被禁用,如果我们有
CAP_SYS_PTRACE能力,我们仍然可以使用它完成利用(实际检查在这里)。当然,一般来说,即使拥有容器root的权限,我们也不太可能获取这个能力…….
Slow page fault
让我们回过头考虑一下到目前为止 userfaultfd 和 FUSE 在我们的漏洞利用过程中所扮演的角色。当内核尝试从用户空间复制数据并遇到页错误时:
- userfaultfd 会导致出错的内核线程暂停,直到我们处理来自用户态的页错误。
- 当内核尝试将错误页加载到内存中时,将调用我们自定义的 FUSE 读取处理程序。
在这两种情况下,我们都可以简单地在copy_from_user()调用处暂停内核线程直到完成其他事情,例如制造对碰。但是是否有可能使页错误花费很长时间,以便我们可以在该时间窗口内完成堆喷?
gctf 2023中提出了利用文件打洞 (Hole Punching)来显着增加页错误造成的延迟:
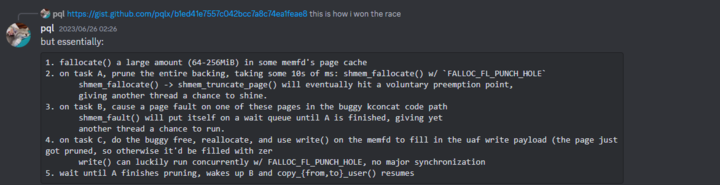
shmem_fault()中的注释解释了为什么会出现这种情况:
1 | |
最终利用
结合上述两个技巧,我们可以得出最终的利用方式:
先随便打开一些文件,比如文件 A,设置权限为
O_RDWR。内核会分配一个相应的file结构体。利用CVE-2022-3910反复减少文件A结构体的引用计数,直到其下溢。这会free结构体但在文件描述符表中仍然保留对它的引用。
注意:这是必需的,因为
fget()(稍后我们提交 AIO 请求时将调用它)如果在引用计数为 0 的file结构体上调用将导致内核停止。代码在这里(检查的宏是get_file_rcu)。使用
memfd_create()创建并获取临时文件 B 的文件描述符,并使用fallocate()为其分配大量内存。使用跨页的缓冲区准备 AIO 请求。第二块页应该由文件 B 控制,并且尚未加载在内存中。
(CPU 1,线程X):使用
FALLOC_FL_PUNCH_HOLE | FALLOC_FL_KEEP_SIZE调用fallocate()加载文件 B。(CPU 1,线程Y):提交AIO请求。这会触发文件 B 所在页的页错误。当文件正在打洞时,线程 Y 会将自己放入等待队列,停止执行,直到线程 X 完成。
(CPU 0,线程 Z):当线程 Y 停止时,重复调用
open()打开/proc/sys/kernel/modprobe来让对应的file结构体覆盖掉文件A的结构体。线程 Y 恢复执行并在
/proc/sys/kernel/modprobe上执行写入。
完整的exp如下: container-escape-using-file-based-DirtyCred.rar
实际利用
标准 Docker 容器
Command:sudo docker run -it --rm ubuntu bash
但是实际上我们的exp并没有起作用,相反,会收到Permission denied。因为在调用aio_setup_rw()后,rw_verify_area()会调用安全钩子函数。默认情况下,Docker 容器在受限的 AppArmor 配置文件下运行,因此额外的权限检查aa_file_perm()失败,导致aio_write()返回而未实际执行写入操作。😥
Docker with apparmor=unconfined
Command:sudo docker run -it --rm --security-opt apparmor=unconfined ubuntu bash
然而,如果 Docker 容器使用apparmor=unconfined运行,那么aa_file_perm()会在实际权限检查发生之前提前退出,从而使我们的漏洞利用能够顺利进行。
这种情况并不是非常有用,因为不太可能有人会特意在已部署的 Docker 容器上禁用 AppArmor。
更实际的场景
Command:sudo ctr run -t --rm docker.io/library/ubuntu:latest bash
如果我们使用直接在 containerd 的 API 之上运行的ctr命令行客户端来启动容器,那么该漏洞利用程序也可以正常工作。这是该技术的一个更现实的利用。🙂
References
- io_uring
- DirtyCred
- https://i.blackhat.com/USA-22/Thursday/US-22-Lin-Cautious-A-New-Exploitation-Method.pdf
- https://blog.hacktivesecurity.com/index.php/2022/12/21/cve-2022-2602-dirtycred-file-exploitation-applied-on-an-io_uring-uaf/
- https://lkmidas.github.io/posts/20210223-linux-kernel-pwn-modprobe/#the-overwriting-modprobe_path-technique
/procfilesystem- Kernel AIO
- fallocate() slow page