概述
人工智能(AI)框架已经有近10年的发展历史,四条主线驱动着AI框架不停地演进和发展:
- 面向开发者:兼顾算法开发的效率和运行性能。
- 面向硬件:充分发挥芯片和集群的性能。
- 面向算法和数据:从计算规模看,需要应对模型越来越大的挑战;从计算范式看,需要处理不断涌现的新的计算负载。
- 面向部署:需要将AI能力部署到每个设备、每个应用、每个行业。
MindSpore是面向“端-边-云”全场景设计的AI框架,旨在弥合AI算法研究与生产部署之间的鸿沟。
在算法研究阶段,为开发者提供动静统一的编程体验以提升算法的开发效率;在生产阶段,自动并行可以极大加快分布式训练的开发和调试效率,同时充分挖掘异构硬件的算力;在部署阶段,基于“端-边-云”统一架构,应对企业级部署和安全可信方面的挑战。
 概述
概述正常业务流程具体如图所示:
执行流程左边蓝色方框的是MindSpore主体框架,主要提供神经网络在训练、验证相关的基础API功能,另外还会默认提供自动微分、自动并行等功能。
蓝色方框往下是MindSpore Data模块,可以利用该模块进行数据预处理,包括数据采样、数据迭代、数据格式转换等不同的数据操作。在训练的过程会遇到很多调试调优的问题,因此有MindSpore Insight模块对loss曲线、算子执行情况、权重参数变量等调试调优相关的数据进行可视化,方便用户在训练过程中进行调试调优。
AI安全最简单的场景就是从攻防的视角来看,例如,攻击者在训练阶段掺入恶意数据,影响AI模型推理能力,于是MindSpore推出了MindSpore Armour模块,为MindSpore提供AI安全机制。
蓝色方框往上的内容跟算法开发相关的用户更加贴近,包括存放大量的AI算法模型库ModelZoo,提供面向不同领域的开发工具套件MindSpore DevKit,另外还有高阶拓展库MindSpore Extend,这里面值得一提的就是MindSpore Extend中的科学计算套件MindSciences,MindSpore首次探索将科学计算与深度学习结合,将数值计算与深度学习相结合,通过深度学习来支持电磁仿真、药物分子仿真等等。
神经网络模型训练完后,可以导出模型或者加载存放在MindSpore Hub中已经训练好的模型。接着有MindIR提供端云统一的IR格式,通过统一IR定义了网络的逻辑结构和算子的属性,将MindIR格式的模型文件 与硬件平台解耦,实现一次训练多次部署。因此如图所示,通过IR把模型导出到不同的模块执行推理。
整体架构
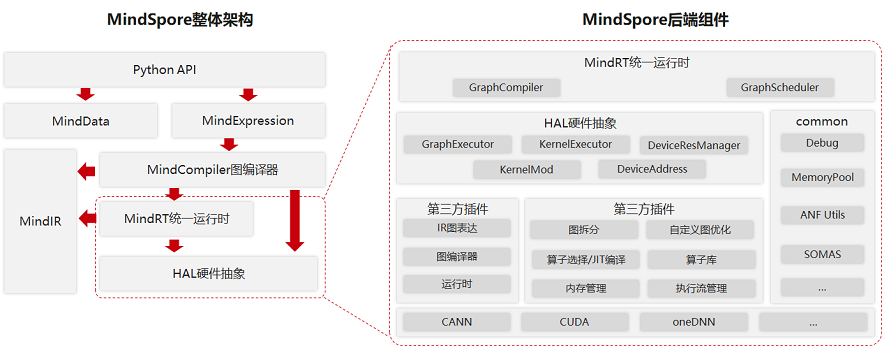
MindSpore整体架构及后端相关组件如下图所示:
整体架构MindSpore整体架构包括如下几个主要组件,它们之间存在相互的依赖关系:
- Python API:提供了基于Python的前端表达与编程接口,支撑用户进行网络构建、整图执行、子图执行以及单算子执行,并通过pybind11接口调用到C++模块,C++模块分为前端、后端、MindData、Core等;
- MindExpression前端表达:负责编译流程控制和硬件无关的优化如类型推导、自动微分、表达式化简等;
- MindData数据组件:MindData提供高效的数据处理、常用数据集加载等功能和编程接口,支持用户灵活的定义处理注册和pipeline并行优化;
- MindIR:包含了ANF IR数据结构、日志、异常等端、云共用的数据结构与算法。
大致可以分为四层:
- 模型层,为用户提供开箱即用的功能,该层主要包含预置的模型和开发套件,以及图神经网络(GNN)、深度概率编程、科学计算库等热点研究领域拓展库;
- 表达层 (MindExpression),为用户提供AI模型开发、训练、推理的接口,支持用户用原生 Python语法开发和调试神经网络,其特有的动静态图统一能力使开发者可以兼顾开发效率和执行性能,同时该层在生产和部署阶段提供全场景统一的C++/Python接口;
- 编译优化(MindCompiler),作为AI框架的核心,以全场景统一中间表达(MindIR)为媒介,将前端表达编译成执行效率更高的底层语言,同时进行全局性能优化,包括自动微分、代数化简等硬件无关优化,以及图算融合、算子生成等硬件相关优化;
- 运行时,按照上层编译优化的结果对接并调用底层硬件算子,同时通过“端-边-云”统一的运行时架构,支持包括联邦学习在内的“端-边-云”AI协同。
安装MindSpore
可以参照官方文档,因配合后续模糊测试,采用源码编译方式安装MindSpore CPU版本。
环境准备-手动
下表列出了编译安装MindSpore所需的系统环境和第三方依赖。
| 软件名称 | 版本 | 作用 |
|---|
| Ubuntu | 18.04 | 编译和运行MindSpore的操作系统 |
| Python | 3.7-3.9 | MindSpore的使用依赖Python环境 |
| wheel | 0.32.0及以上 | MindSpore使用的Python打包工具 |
| setuptools | 44.0及以上 | MindSpore使用的Python包管理工具 |
| GCC | 7.3.0到9.4.0之间 | 用于编译MindSpore的C++编译器 |
| git | - | MindSpore使用的源代码管理工具 |
| CMake | 3.18.3及以上 | 编译构建MindSpore的工具 |
| tclsh | - | MindSpore sqlite编译依赖 |
| patch | 2.5及以上 | MindSpore使用的源代码补丁工具 |
| NUMA | 2.0.11及以上 | MindSpore使用的非一致性内存访问库 |
| LLVM | 12.0.1 | MindSpore使用的编译器框架(可选,图算融合以及稀疏计算需要) |
下面给出第三方依赖的安装方法。
安装Python
Python可通过多种方式进行安装。
可以通过以下命令查看Python版本。
在安装完成Python后,使用以下命令安装。
1
2
| pip install wheel
pip install -U setuptools
|
安装GCC git tclsh patch和NUMA
可以通过以下命令安装GCC,git,tclsh,patch和NUMA。
1
| sudo apt-get install gcc-7 git tcl patch libnuma-dev -y
|
如果要安装更高版本的GCC,使用以下命令安装GCC 8。
1
| sudo apt-get install gcc-8 -y
|
或者安装GCC 9。
1
2
3
4
| sudo apt-get install software-properties-common -y
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install gcc-9 -y
|
安装CMake
可以通过以下命令安装CMake。
1
2
3
| wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | sudo apt-key add -
sudo apt-add-repository "deb https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main"
sudo apt-get install cmake -y
|
安装LLVM-可选
可以通过以下命令安装LLVM。
1
2
3
4
| wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add -
sudo add-apt-repository "deb http://apt.llvm.org/bionic/ llvm-toolchain-bionic-12 main"
sudo apt-get update
sudo apt-get install llvm-12-dev -y
|
从代码仓下载源码
1
| git clone https://gitee.com/mindspore/mindspore.git
|
编译MindSpore
进入mindspore根目录,然后执行编译脚本。
1
2
| cd mindspore
bash build.sh -e cpu -j4 -S on
|
其中:
- 如果编译机性能较好,可在执行中增加-j{线程数}来增加线程数量。如
bash build.sh -e cpu -j12。 - 默认从github下载依赖源码,当-S选项设置为
on时,从对应的gitee镜像下载。 - 关于
build.sh更多用法请参看脚本头部的说明。
安装MindSpore
1
| pip install output/mindspore-*.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
|
在联网状态下,安装whl包时会自动下载mindspore安装包的依赖项(依赖项详情参见setup.py中的required_package),其余情况需自行安装。运行模型时,需要根据ModelZoo中不同模型指定的requirements.txt安装额外依赖,常见依赖可以参考requirements.txt。
验证安装是否成功
1
| python -c "import mindspore;mindspore.set_context(device_target='CPU');mindspore.run_check()"
|
如果输出:
1
2
| MindSpore version: 版本号
The result of multiplication calculation is correct, MindSpore has been installed on platform [CPU] successfully!
|
说明MindSpore安装成功了。
升级MindSpore版本
在源码根目录下执行编译脚本build.sh成功后,在output目录下找到编译生成的whl安装包,然后执行下述命令进行升级。
1
| pip install --upgrade mindspore-*.whl
|
威胁分析与模糊测试
通过业界对AI框架软件Tensorflow安全研究成果和上述的整体架构,抽取出MindSpore所面临的安全风险和漏洞模式。
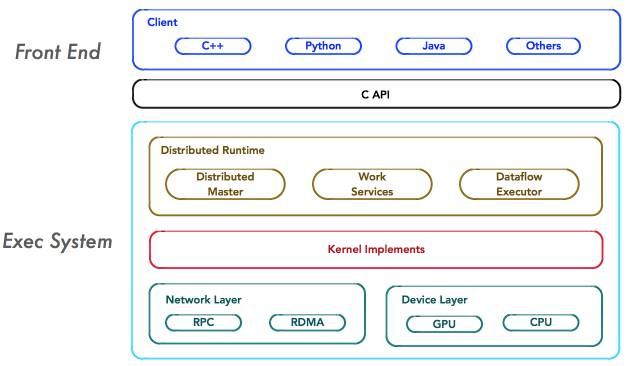
TensorFlow的系统结构以C API为界,将整个系统分为「前端」和「后端」两个子系统:
前端系统:提供编程模型,负责构造计算图;
后端系统:提供运行时环境,负责执行计算图。
Tensorflow架构如上图所示,重点关注系统中如下4个基本组件,它们是系统分布式运行机制的核心。
Client Client是前端系统的主要组成部分,它是一个支持多语言的编程环境。它提供基于计算图的编程模型,方便用户构造各种复杂的计算图,实现各种形式的模型设计。Client通过Session为桥梁,连接TensorFlow后端的「运行时」,并启动计算图的执行过程。
Distributed Master 在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的「最小子图」。然后,Distributed Master负责将该「子图」再次分裂为多个「子图片段」,以便在不同的进程和设备上运行这些「子图片段」。最后,Distributed Master将这些「子图片段」派发给Work Service;随后Work Service启动「子图片段」的执行过程。
Worker Service 对于每以个任务,TensorFlow都将启动一个Worker Service。Worker Service将按照计算图中节点之间的依赖关系,根据当前的可用的硬件环境(GPU/CPU),调用OP的Kernel实现完成OP的运算(一种典型的多态实现技术)。另外,Worker Service还要负责将OP运算的结果发送到其他的Work Service;或者接受来自其他Worker Service发送给它的OP运算的结果。
Kernel Implements Kernel是OP在某种硬件设备的特定实现,它负责执行OP的运算。
通过对业界Tensorflow漏洞进行分析,可总结出主要漏洞模式为构造恶意参数传递给python API,恶意参数通过数据流传递到后端C++内核,导致后端出现传统编码错误。因此我们可以将模糊测试的重点放在算子和模型转换与解析,分别对应MindSpore的api接口以及MindSpore Lite的converter工具,模糊测试工具我们选择Atheris: A Coverage-Guided, Native Python Fuzzer以及AFLPlusPlus(或者honggfuzz等)。
编译插桩版本
MSLITE编译
1
2
3
4
5
6
7
8
9
10
11
12
| export CFLAGS=-w
export CXXFLAGS=-w
export CC=afl-gcc-fast
export CXX=afl-g++-fast
export MSLITE_ENABLE_TRAIN=off
export MSLITE_ENABLE_CONVERTER=on
export MSLITE_ENABLE_TOOLS=on
export MSLITE_ENABLE_MODEL_OBF=on
export MSLITE_ENABLE_MODEL_ENCRYPTION=on
export MSLITE_ENABLE_MODEL_PRE_INFERENCE=on
bash build.sh -I x86_64 -d -a on -j$(nproc)
|
MindSpore编译
1
2
3
4
5
6
| export CFLAGS=-w
export CXXFLAGS=-w
export CC=gcc
export CXX=g++
bash build.sh -e cpu -d -c on -a on -j$(nproc)
|
进行模糊测试
使用Atheris对python API测试
参照python_fuzzing.py编写辅助测试脚本
构造恶意Tensor对算子测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| """This is a Python API fuzzer template for mindspore.ops.abs"""
import atheris
with atheris.instrument_imports():
import sys
from python_fuzzing import FuzzingHelper
import mindspore as ms
def TestOneInput(data):
"""Test randomized fuzzing input for tf.raw_ops.Abs."""
fh = FuzzingHelper(data)
input_tensor = fh.get_random_numeric_tensor(dtype=ms.float32)
_ = ms.ops.abs(input=input_tensor)
def main():
atheris.Setup(sys.argv, TestOneInput)
atheris.Fuzz()
if __name__ == "__main__":
main()
|
构造恶意模型对加载接口测试
编写MINDIR的proto文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
| syntax = "proto2";
package mind_ir;
enum Version {
IR_VERSION_START = 0;
IR_VERSION = 1;
}
message AttributeProto {
enum AttributeType {
UNDEFINED = 0;
FLOAT = 1;
UINT8 = 2;
INT8 = 3;
UINT16 = 4;
INT16 = 5;
INT32 = 6;
INT64 = 7;
STRING = 8;
BOOL = 9;
FLOAT16 = 10;
DOUBLE = 11;
UINT32 = 12;
UINT64 = 13;
COMPLEX64 = 14;
COMPLEX128 = 15;
BFLOAT16 = 16;
TENSOR = 17;
GRAPH = 18;
TENSORS = 19;
TUPLE = 20;
LIST = 21;
DICT = 22;
UMONAD = 23;
IOMONAD = 24;
NONE = 25;
PRIMITIVECLOSURE = 26;
FUNCGRAPHCLOSURE = 27;
PARTIALCLOSURE = 28;
UNIONFUNCCLOSURE = 29;
CSR_TENSOR = 30;
COO_TENSOR = 31;
ROW_TENSOR = 32;
CLASS_TYPE = 33;
NAME_SPACE = 34;
SYMBOL = 35;
TYPE_NULL = 36;
MAP_TENSOR = 37;
FUNCTOR = 38;
SCALAR = 39;
}
message SeqInfoProto{
optional bool is_dyn_len = 1;
optional AttributeProto tuple_elem_item = 2;
}
optional string name = 1;
optional float f = 2;
optional int64 i = 3;
optional double d = 4;
optional bytes s = 5;
optional TensorProto t = 6;
optional GraphProto g = 7;
repeated float floats = 8;
repeated double doubles = 9;
repeated int64 ints = 10;
repeated bytes strings = 11;
repeated TensorProto tensors = 12;
repeated GraphProto graphs = 13;
optional string doc_string = 14;
optional string ref_attr_name = 15;
optional AttributeType type = 16;
repeated AttributeProto values = 17;
optional SeqInfoProto seq_info = 18;
optional FunctorProto functor = 19;
}
message FunctorProto {
enum FunctorType {
SHAPE_CALC_FUNCTOR = 1;
}
optional FunctorType type = 1;
optional string name = 2;
repeated AttributeProto values = 3;
}
message ValueInfoProto {
optional string name = 1;
repeated TensorProto tensor = 2;
optional string doc_string = 3;
optional string denotation = 4;
optional AttributeProto attr_info = 5;
}
message NodeProto {
repeated string input = 1;
repeated string output = 2;
optional string name = 3;
optional string op_type = 4;
repeated AttributeProto attribute = 5;
optional string doc_string = 6;
optional string domain = 7;
repeated AttributeProto node_attr = 8;
repeated AttributeProto primal_attr = 9;
}
message ModelProto {
optional string ir_version = 1;
optional string producer_name = 2;
optional string producer_version = 3;
optional string domain = 4;
optional string model_version = 5;
optional string doc_string = 6;
optional GraphProto graph = 7;
repeated GraphProto functions = 8;
optional PreprocessorProto preprocessor = 9;
optional bool little_endian = 10;
optional ParallelProto parallel = 11;
repeated PrimitiveProto primitives = 12;
optional int64 mind_ir_version = 13;
}
message PreprocessorProto {
repeated PreprocessOpProto op = 1;
}
message PreprocessOpProto {
optional string input_columns = 1;
optional string output_columns = 2;
optional string project_columns = 3;
optional string op_type = 4;
optional string operations = 5;
optional bool offload = 6;
}
message GraphProto {
repeated NodeProto node = 1;
optional string name = 2;
repeated TensorProto parameter = 3;
optional string doc_string = 4;
repeated ValueInfoProto input = 5;
repeated ValueInfoProto output = 6;
optional string bprop_hash = 7;
repeated AttributeProto attribute = 8;
optional string bprop_filepath = 9;
repeated MapTensorProto map_parameter = 10;
}
message TensorProto {
enum DataType {
UNDEFINED = 0;
FLOAT = 1;
UINT8 = 2;
INT8 = 3;
UINT16 = 4;
INT16 = 5;
INT32 = 6;
INT64 = 7;
STRING = 8;
BOOL = 9;
FLOAT16 = 10;
DOUBLE = 11;
UINT32 = 12;
UINT64 = 13;
COMPLEX64 = 14;
COMPLEX128 = 15;
BFLOAT16 = 16;
FLOAT64 = 17;
}
enum CompressionType {
NO_COMPRESSION = 0;
INDEXING = 1;
SPARSE = 2;
FSE = 3;
BIT_PACKING = 4;
FSE_INT = 5;
FSE_INFER = 6;
}
message ExternalDataProto {
optional string location = 1;
optional int64 offset = 2;
optional int64 length = 3;
optional string checksum = 4;
}
message QuantParamProto {
required string quant_algo_name = 1;
repeated AttributeProto attribute = 2;
}
repeated int64 dims = 1;
optional int32 data_type = 2;
repeated float float_data = 3;
repeated int32 int32_data = 4;
repeated bytes string_data = 5;
repeated int64 int64_data = 6;
optional string name = 7;
optional string doc_string = 8;
optional bytes raw_data = 9;
repeated double double_data = 10;
repeated uint64 uint64_data = 11;
optional ExternalDataProto external_data = 12;
optional string ref_key = 13;
repeated int64 min_dims = 14;
repeated int64 max_dims = 15;
optional CompressionType compression_type = 16;
repeated QuantParamProto quant_params = 17;
}
message MapTensorProto {
required string name = 1;
required AttributeProto default_value = 2;
required TensorProto key_tensor = 3;
required TensorProto value_tensor = 4;
required TensorProto status_tensor = 5;
}
message ParallelProto {
repeated LayoutProto layout = 1;
}
message LayoutProto {
optional string name = 1;
repeated int64 device_arrangement_int = 2;
repeated int64 tensor_map_int = 3;
repeated int64 slice_shape_int = 4;
optional int64 field_size = 5;
optional bool uniform_split = 6;
optional string opt_shard_group = 7;
}
message PrimitiveProto {
optional string name = 1;
optional string op_type = 2;
repeated AttributeProto attribute = 3;
optional string instance_name = 4;
}
|
使用Libprotobuf-mutator辅助测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| """This is a Python API fuzzer template with protobuf for mindspore.load"""
import atheris
import sys
import numpy as np
import os
import atheris_libprotobuf_mutator
import mind_ir
with atheris.instrument_imports():
import mindspore as ms
_DEFAULT_FILENAME = '/tmp/test.mindir'
@atheris.instrument_func
def TestOneProtoInput(data):
with open(_DEFAULT_FILENAME,mode='w') as f:
f.write(data.SerializeAsString())
try:
_ = ms.load(filename = _DEFAULT_FILENAME)
except:
return
if __name__ == '__main__':
atheris_libprotobuf_mutator.Setup(
sys.argv, TestOneProtoInput, proto=mind_ir.ModelProto)
atheris.Fuzz()
|
atheris的命令行参数与libfuzzer一致,参照官方文档配置即可。
使用AFL对端侧推理框架测试
配置环境变量,以converter为例进行fuzz
1
2
3
| export LD_LIBRARY_PATH=$PWD/output/tmp/mindspore-lite-2.1.0-linux-x64/runtime/lib:$PWD/output/tmp/mindspore-lite-2.1.0-linux-x64/tools/converter/lib
afl-fuzz -i mindir_corpus -o outdir -- ./output/tmp/mindspore-lite-2.1.0-linux-x64/tools/converter/converter/converter_lite --fmk=MINDIR --modelFile=@@ --outputFile=/dev/null
|