WSL2下AFL的安装与测试
简介
AFL号称是当前最高级的Fuzzing测试工具之一,由lcamtuf所开发。在众多安全会议白帽演讲中都介绍过这款工具,以及2016年defcon大会的CGC(Cyber Grand Challenge,形式为机器自动挖掘并修补漏洞)大赛中多支队伍利用AFL fuzzing技术与符号执行(Symbolic Execution)来实现漏洞挖掘,其中参赛队伍shellphish便是采用AFL(Fuzzing) + angr(Symbolic Execution)技术。
本文首先简单介绍一下AFL的安装步骤和基本使用方法,随后以ntpq为例记录一下使用AFL来fuzz的过程并对CVE-2009-0159进行了复现和原理分析。
AFL下载与安装
AFL可以对有源码和无源码的程序进行fuzz。对有源码的程序Fuzz的原理简单来说就是在程序编译时,向汇编代码中插入自己的指令,从而在程序运行时,计算覆盖率。当把样本喂给程序来Fuzz时,如果AFL发现程序执行了新的路径,就把当前的样本保存在Queue中,基于这个新的样本来继续Fuzz。[1]
与其他基于插桩技术的fuzzers相比,afl-fuzz具有较低的性能消耗,有各种高效的fuzzing策略和tricks最小化技巧,不需要先行复杂的配置,能无缝处理复杂的现实中的程序。当然AFL也可以直接对没有源码的二进制程序进行测试,但需要QEMU的支持。
本体安装与测试
1 | |
which afl-fuzz有回显即安装成功
推荐去Github[2]上下载,一直在维护,安装过程相同。(截止发文,最新版为v2.57b)
Ps. Kali的源中包含afl,可以直接尝试 apt install afl。
测试
- 新建输入、输出文件夹:
mkdir in out - 准备初始化testcase, 将testcase内容随意写成aaa:
echo aaa > in/testcase
随便找个代码编译测试
1 | |
启动afl-fuzz中可能会报错,表示某些环境变量没有配置或者配置错误,根据提示修改或配置afl-fuzz options以及系统环境变量即可。
结果大概如下:
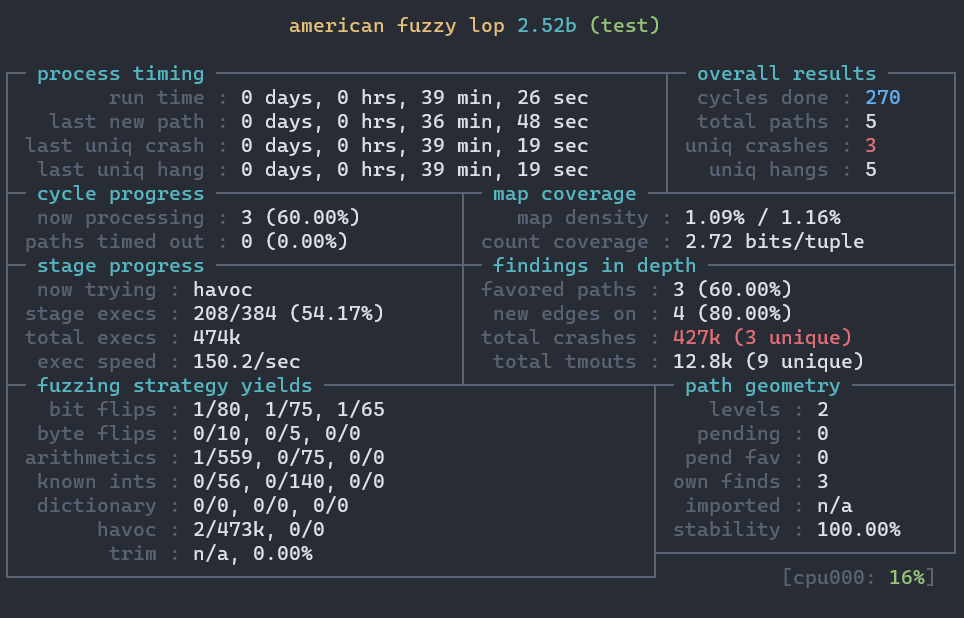
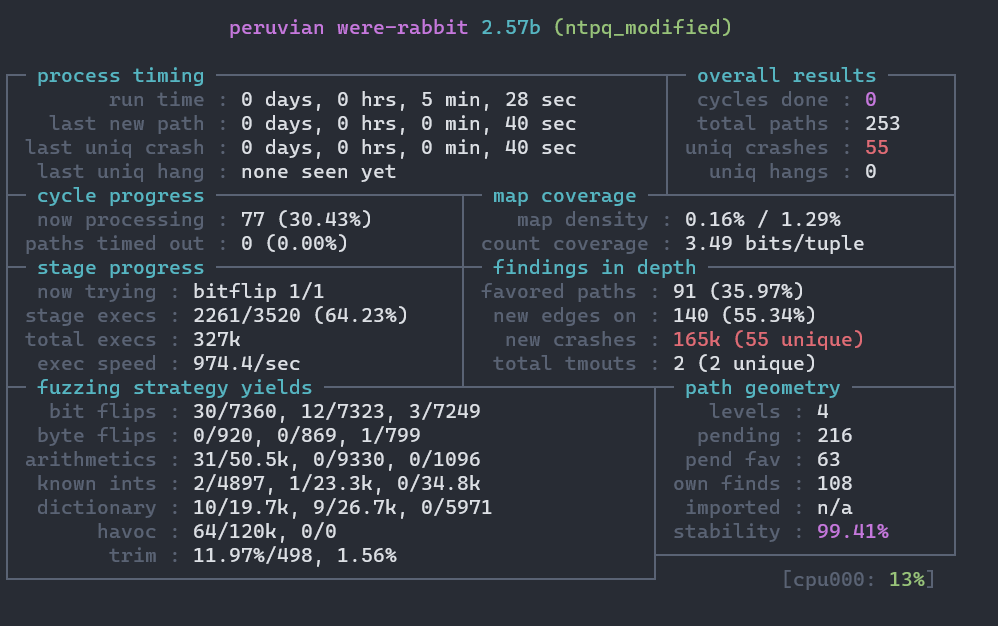
工作状态
afl-fuzz永远不会停止,所以何时停止测试很多时候就是依靠afl-fuzz提供的状态来决定的。具体的几种方式如下所示:
- 状态窗口的
cycles done变为绿色; afl-whatsup查看afl-fuzz状态;afl-stat得到类似于afl-whatsup的输出结果;- 定制
afl-whatsup->在所有代码外面加个循环就好; - 用
afl-plot绘制各种状态指标的直观变化趋势; pythia估算发现新crash和path概率。
fuzzing结束时机参考
- 状态窗口中”cycles done”字段颜色变为绿色该字段的颜色可以作为何时停止测试的参考;
- 距上一次发现新路径(或者崩溃)已经过去很长时间了,至于具体多少时间还是需要自己把握;
- 目标程序的代码几乎被测试用例完全覆盖,这种情况好像很少见;
- pythia提供的各种数据中,path covera达到99或者correctness的值达到1e-08(含义: 从上次发现path/uniq crash到下一次发现之间大约需要1亿次执行)
输出结果说明
- queue:存放所有具有独特执行路径的测试用例。
- crashes:导致目标接收致命signal而崩溃的独特测试用例。
- crashes/README.txt:保存了目标执行这些crash文件的命令行参数。
- hangs:导致目标超时的独特测试用例。
- fuzzer_stats:afl-fuzz的运行状态。
- plot_data:用于afl-plot绘图。
AFL工作原理简介
Fuzz流程:
- 读取输入的初始testcase, 将其放入到queue中;
- 从queue中读取内容作为程序输入;
- 尝试在不影响流程的情况下精简输入;
- 对输入进行自动突变;
- 如果突变后的输入能够有新的状态转移,将修改后的输入放入queue中;
- 回到2。
在使用AFL 编译工具 afl-gcc对源码进行编译时,程序会使用afl-as工具对编译并未汇编的c/c++代码进行插桩。过程如下:
- afl-as.h定义了被插入代码中的汇编代码;
- afl-as逐步分析.s文件(汇编代码),检测代码特征并插入桩。
详细过程:
- 编译预处理程序对源文件进行预处理,生成预处理文件(.i文件)
- 编译插桩程序对.i文件进行编译,生成汇编文件(.s文件),afl同时完成插桩
- 汇编程序(as)对.s文件进行汇编,生成目标文件(.o文件)
- 链接程序(ld)对.o文件进行连接,生成可执行文件(.out/.elf文件)
当然llvm/clang插桩方式是另外的一套机制,通过修改LLVM IR(中间语言)实现。
LLVM Mode
LLVM Mode(afl-clang)模式编译程序Fuzzing速度是afl-gcc模式的2倍,但是使用此模式必须先安装llvm套件,配置LLVM_CONFIG(export LLVM_CONFIG=which llvm-config),然后在afl/llvm_mode/文件夹下执行make,会在afl目录下生成afl-clang-fast/afl-clang-fast++。 使用afl-clang-fast编译C程序:
1 | |
最后还是会调用clang/clang++来编译程序,在编译程序时会检查编译选项(makefile中的CFLAGS),clang提供很多内存检查的工具如ASAN/MSAN/UBSAN等,以及afl编译选项AFL_QUIET(Qemu模式),这些选项可以直接填写进makefile的编译选项也可以设置到环境变量中,afl-gcc/afl-clang在开始编译前会检查这些环境变量。
Ps. 如果出现了error: clang frontend command failed due to signal (use -v to see invocation)错误可以换成GitHub上的最新版本再次尝试。(2.57b版本已修复)
Qemu Mode
在无源码的情况下Fuzzing二进制文件,需要安装glib2-devel libtool wget python automake autoconf sha384sum bison iconv等依赖
1 | |
使用apt安装缺失的库即可,如sudo apt install libglib2*(glib2) 或 sudo apt-get install libtool* (libtool)。
当出现util/memfd.c错误时,可参照以下方法[3](2.57b版本已修复)
创建一个名为“memfd_create.diff”的文件,然后将下列代码粘贴进去:
1 | |
将memfd_create.diff放在patches/目录下后修改build_qemu_support.sh
1 | |
然后再次运行build_qemu_support.sh即可
如遇其他问题可以Google后反馈在评论区,我能解决的问题都会回复。
ntp-4.2.2 测试
NTP是一种旨在通过网络同步计算机时钟的协议。我们将使用afl对其部件ntpq进行白盒测试以尝试复现CVE-2009-0159[4],测试版本为v4.2.2,可点击此处下载。
ntpq is a utility included as part of the NTP Reference Implementation suite of tools. It queries a server (e.g. ntpd) and provides information to the user.
编译测试
为加快测试速度,我们只编译测试ntpq部分:
1 | |
你可以在几分钟内找到CVE-2009-0159而无需进一步的工作,尤其是在使用persistent mode时。但当你不够欧时(比如说我),就可能跑到自闭。。。还会多出很多无用的输出文件。(虽然我运行时间确实不长)
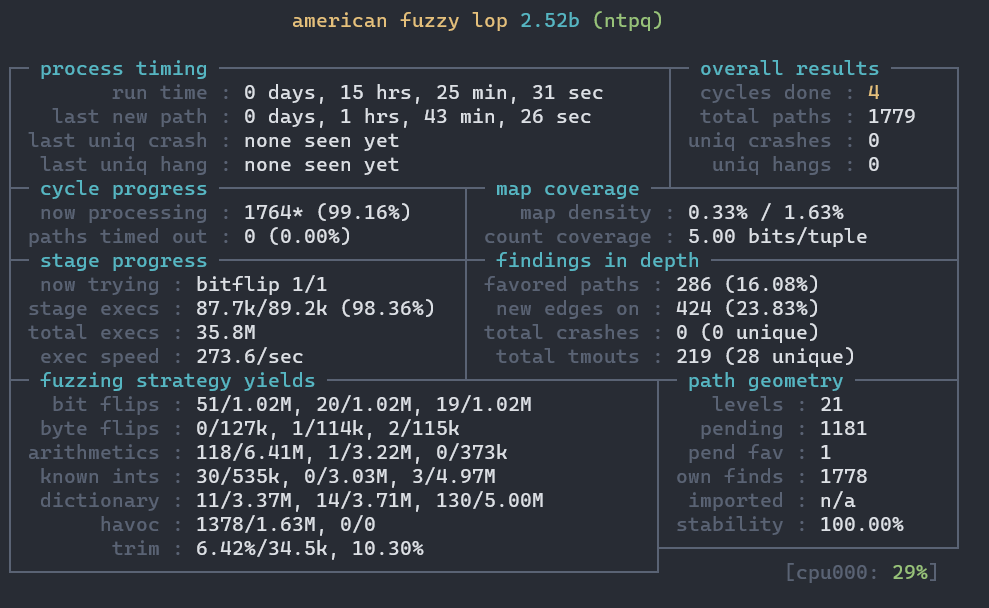
优化
多核并行
查看系统核心数
1 | |
afl-fuzz并行Fuzzing一般的做法是通过-M参数指定一个主Fuzzer(Master Fuzzer)、通过-S参数指定多个从Fuzzer(Slave Fuzzer)。
1 | |
PS. -o指定的是一个同步目录,在并行测试中所有的Fuzzer将相互协作,找到新的代码路径时会相互传递新的测试用例,所以不用担心重复的问题。
afl-whatsup可以查看每个fuzzer的运行状态和总体运行概况,加上-s选项只显示概况,其中的数据都是所有fuzzer的总和。afl-gotcpu可以查看每个核心使用状态。
源码优化
与其尝试让afl的输出去模拟ntpd程序,不如直接将ntpq/ntpq.c中的main()函数替换为从stdin读取数据类型,状态和数据并将输出文件作为stdout的代码。这也是测试network program的常见方法——隔离测试解析器之类的目标功能。
将nptqmain()替换如下:
1 | |
16kb的缓冲区大小可以随意改变,过小的缓冲区可以加快测试速度,但也可能错过某些Bug。
将下述代码添加到nextvar的开头可以确保这些静态变量不会保留从一次运行到下一次运行的数据,从而显著改善性能。
1 | |
字典
在没有任何帮助的情况下afl会耗费很长时间才能找到可以从varfmt返回的所有不同格式,所以我们可以在项目中检测一些可用的字符串到字典中供afl使用,如:
1 | |
使用-x命令调用字典。
1 | |
借助该字典,我们能找到的路径数量会大大增加。
测试
重新编译后再次运行fuzz:
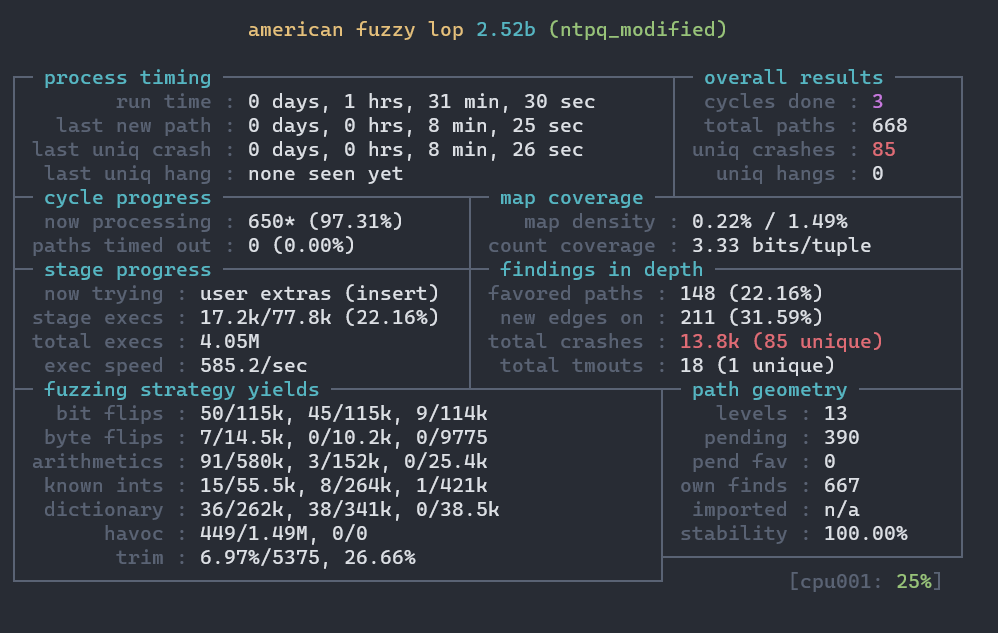
可以发现搜寻效率与之前相比有了巨大的提升,继续运行:
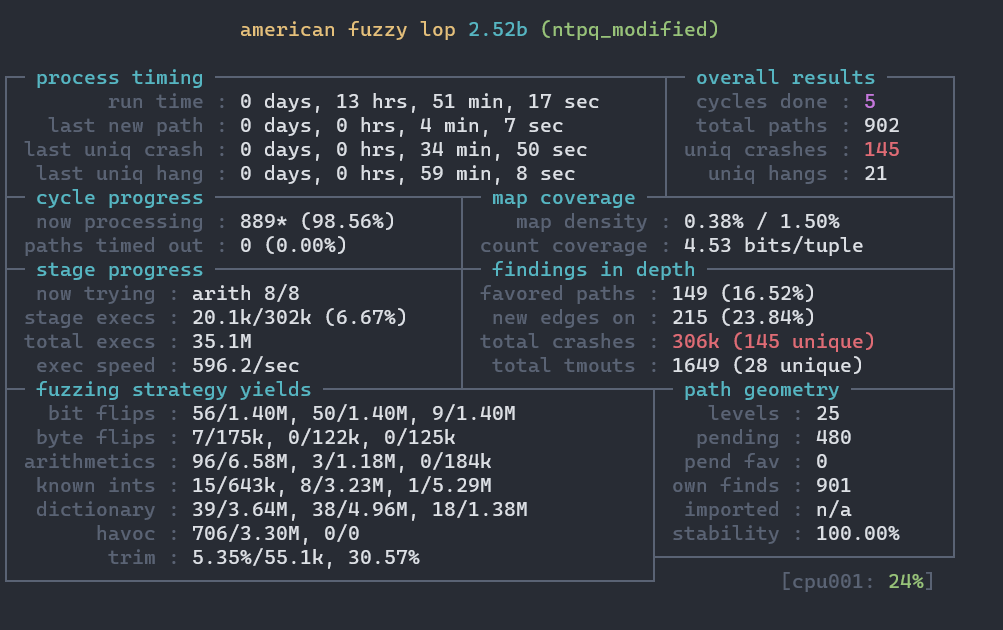
结果分析
到了这里,我们已经跑出了一大堆的crashes,那么接下来自然是确定造成这些crashes的bug是否可以利用以及怎么利用。后者可能会要困难得多,这需要对常见的二进制漏洞类型、操作系统的安全机制、代码审计和调试等内容都有一定深度的了解。但如果只是对crash做简单的分析和分类,那么下面介绍的几种方法都可以提供一些帮助。
crash exploration mode
这是afl-fuzz的一种运行模式,也称为peruvian rabbit mode,用于确定bug的可利用性,具体细节可以参考lcamtuf的博客。
1 | |
举个例子,当你发现目标程序尝试写入,那么就可以猜测这个bug应该是可以利用的;然而遇到例如NULL pointer dereferences这样的漏洞就没那么容易判断了。
将一个导致crash测试用例作为afl-fuzz的输入,使用-C选项开启crash exploration模式后,可以快速地产生很多和输入crash相关、但稍有些不同的crashes,从而判断能够控制某块内存地址的长度。该文章中有一个很不错的例子——tcpdump栈溢出漏洞,crash exploration模式从一个crash产生了42个新的crash,并读取不同大小的相邻内存。
triage_crashes
AFL源码的experimental目录中有一个名为triage_crashes.sh的脚本,可以帮助我们触发收集到的crashes。例如下面的例子中,11代表了SIGSEGV信号,有可能是因为缓冲区溢出导致进程引用了无效的内存。而其他如06代表了SIGABRT信号,可能是执行了abortfree导致。
1 | |
crashwalk
当然上面的两种方式都过于鸡肋了,如果你想得到更细致的crashes分类结果,以及导致crashes的具体原因,那么crashwalk就是不错的选择之一。这个工具基于gdb的exploitable插件,安装也相对简单(但我懒得装),具体方法可以参考工具的安装文档。
crashwalk支持AFL/Manual两种模式。前者通过读取crashes/README.txt文件获得目标的执行命令,后者则可以手动指定一些参数。两种使用方式如下:
1 | |
两种模式的输出结果都一样,也比前面几种方法要详细多了,但当有大量crashes时结果还是显得十分混乱。
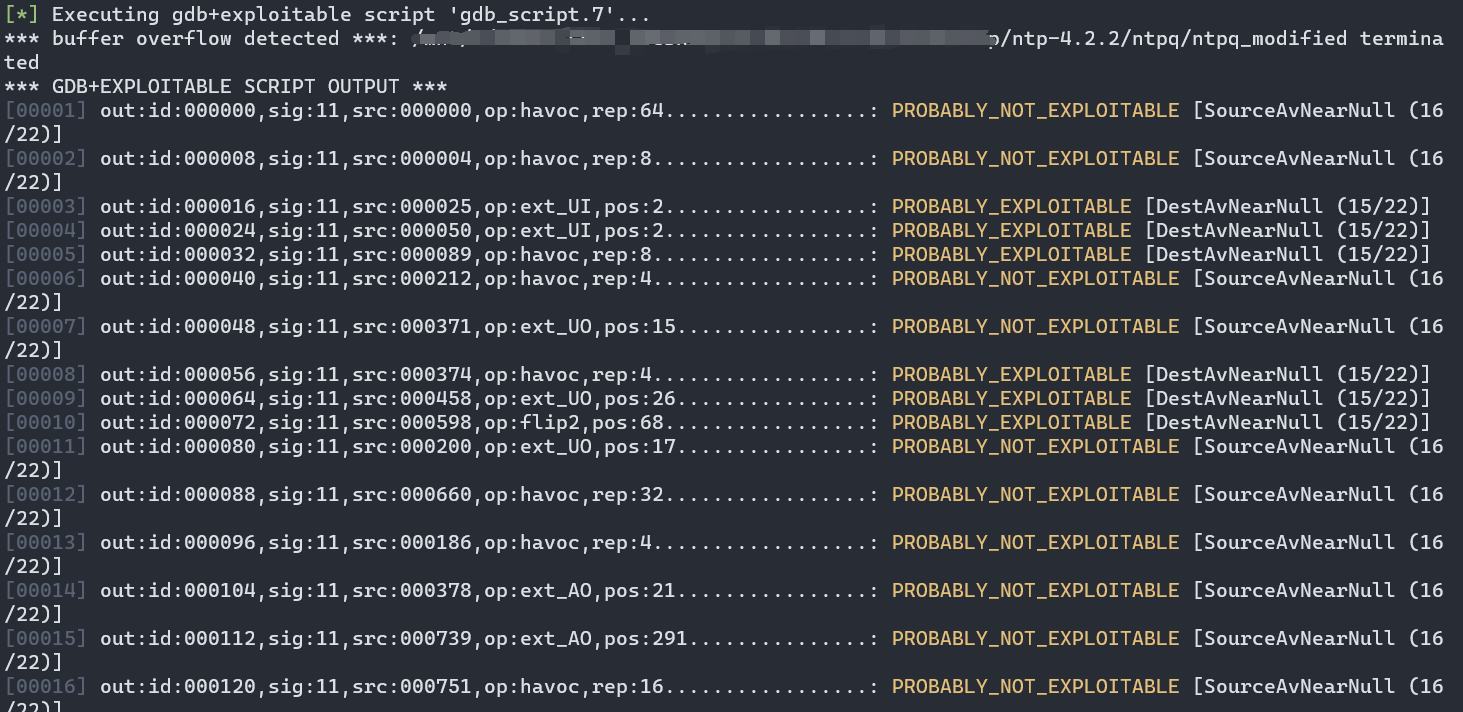
afl-collect
最后重磅推荐的工具便是afl-collect,它也是afl-utils套件中的一个工具,同样也是基于exploitable来检查crashes的可利用性。它可以自动删除无效的crash样本、删除重复样本以及自动化样本分类。使用起来命令稍微长一点,如下所示:
1 | |
但是结果就像下面这样非常直观:
漏洞分析
1 | |
程序使用while循环迭代检索data缓冲区的下一个变量,然后调用findvar()判断name是否已知。当返回不为0时,它会跳转到else并将fmt设置为ctl_var结构中的相应变量。当该格式为0C时(#define OC 12 /* integer, print in octal */),它将调用decodeuint从value中解码一个无符号整数并将结果存储到uval无符号long中。如果失败,它将跳到else部分,在该部分中会声明一个10字节大小的本地缓冲区,然后尝试向其中写入解析为有符号八进制长整型的uval。这意味着我们可以写入不包括NULL的11个字节。由于缓冲区b只有10个字节长,因此上面的代码可能会出现off-by-two overflow,后面对output()的调用只是将name = b传给到fp。
补丁
将代码修改如下即可。
1 | |
增加缓冲区大小并使用更为安全的snprintf函数。